
.jpg)



Email Marketing
Email marketing tactics to help you grow sales for your store
Email Marketing
Oct 13, 2023
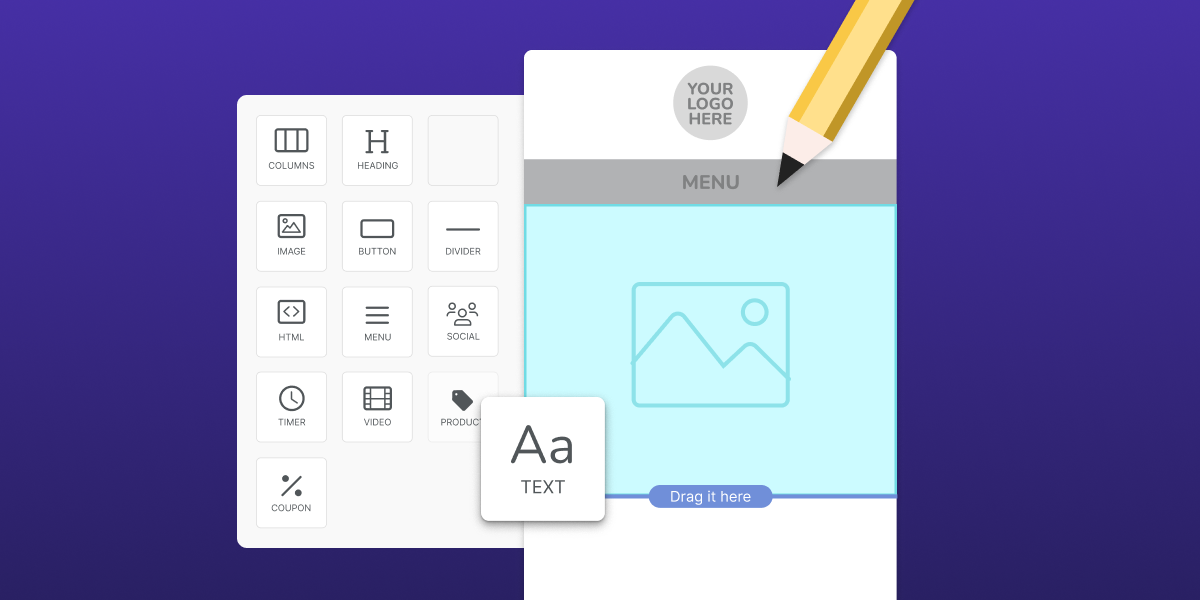
How to Create a Stunning Email With Privy: 15+ Design Tips and Best Practices
A well-designed email is key to communicating with your audience, building engagement and trust, and driving sales. Learn these 15+ tips and tricks for creating beautiful and effective emails in Privy.
Email Marketing
Aug 29, 2023
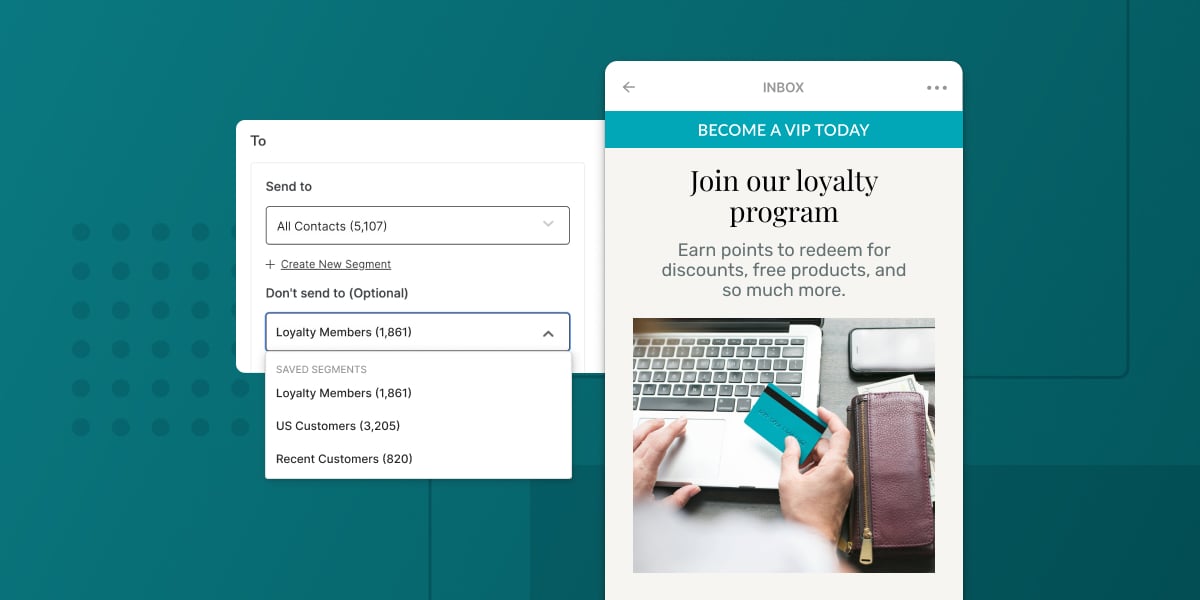
When to Exclude a Segment from Your Campaigns (+ Simple Tips for Email Segmentation in Privy)
Excluding a segment of contacts from certain campaigns gives you greater control who does and doesn't receive your marketing messages. Learn when and how to exclude segments from your campaigns with Privy.

Email Marketing
Aug 17, 2023
5 Ways To Turn Your Unengaged Subscribers Into Active Members of Your List (Plus 21 Subject Line Ideas)
It’s easier to re-engage subscribers who already have an affinity for your brand than it is to win over new contacts. Get 5 campaign and 21 subject line ideas to you turn unengaged subscribers into active members of your list.

Email Marketing
Feb 22, 2023
5 email marketing lessons from customers' top campaigns
Privy customers send 100+ million emails each month. Get tips and lessons you can apply from customers' best performing email campaigns in 2022.
SMS Marketing
Sell to shoppers on the devices they use most – their smartphones
SMS Marketing
Jul 15, 2022
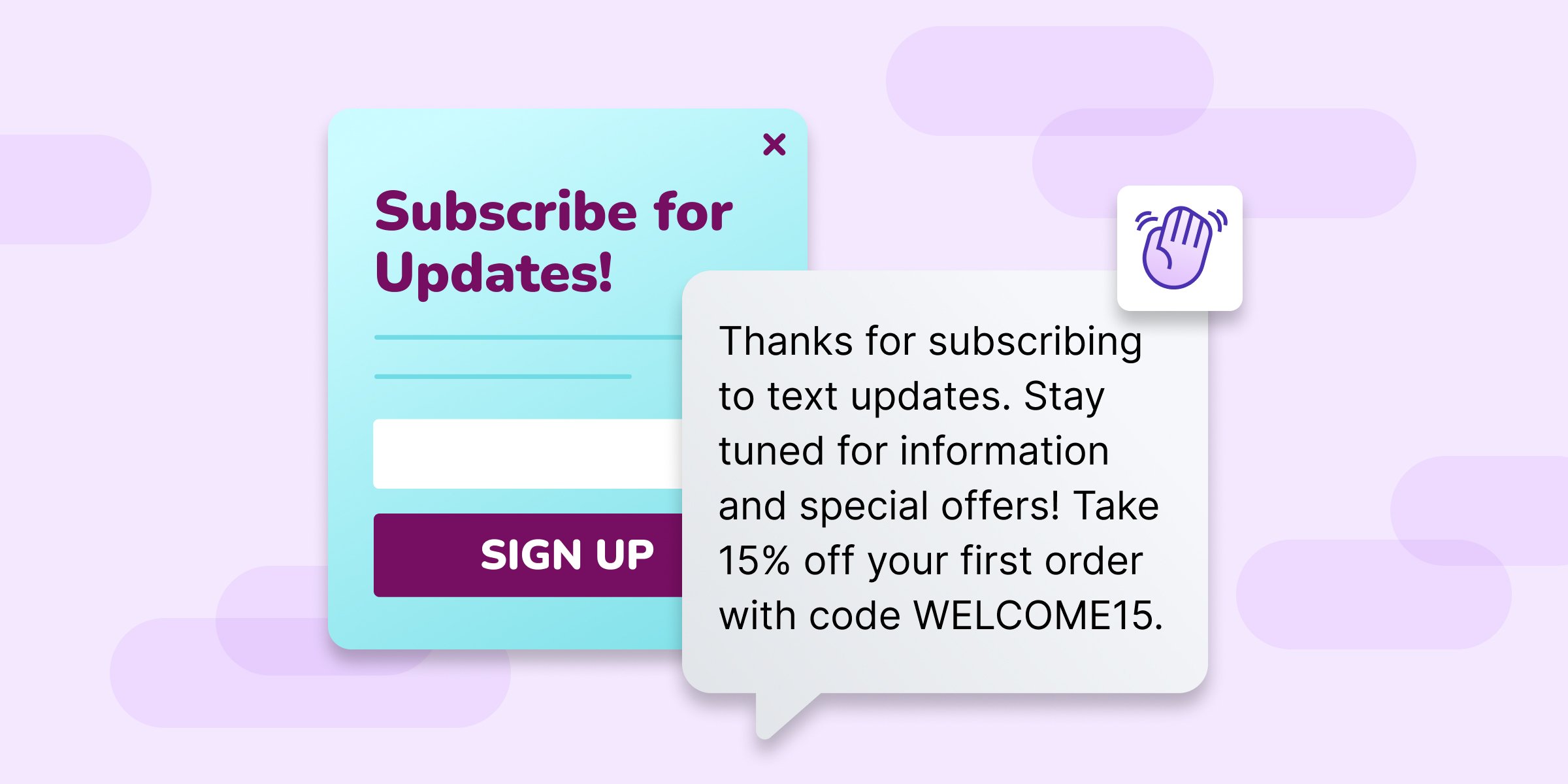
6 Ways To Grow Your SMS List And Crush Text Marketing ASAP
Getting started with SMS marketing can feel daunting. But step 1 is to grow your list. Luckily, there’s so much you can do to grow your list. Here are 6 ways to get new subscribers ASAP.

SMS Marketing
Jun 07, 2022
The 10 Best Times To Send Your SMS Marketing
Like anything, timing matters when it comes to your SMS marketing. So how do you pick the best times? Use these 10 tips to bring in sales and find the perfect send times for your store.

SMS Marketing
Feb 02, 2022
What Is SMS Marketing? Get Customers to Buy from Their Phones
With much higher open rates than email, SMS marketing can be hugely beneficial. Here's what you need to know about using SMS for your ecommerce brand.

Ecommerce Marketing
Feb 01, 2022
Finding the Perfect Balance for Email & SMS Marketing
Email and SMS are incredible channels for ecommerce stores. But how should you be using them together and which messages are best for each? Here's how you can find the perfect balance.
List Growth
Proven strategies to help you turn browsers into subscribers.

BFCM
Sep 08, 2023
9 Proven Ways To Grow Your Email And SMS Lists Before BFCM
The more contacts you have, the more revenue you’ll bring in with every email and text you send. That’s why list growth is especially important before Black Friday. Try these 9 proven tactics to grow your email and SMS lists ASAP.

Product
Apr 07, 2021
How To Grow Your Email List Fast | Privy
Email marketing should drive significant revenue for your ecommerce business. But to get there, you need to have an email list. Find out how you can grow your email list with Privy.

List Growth
Dec 04, 2020
Why You Should Be Using Tabs With Your Popups: How One Brand Got an Extra 1k Subscribers in 30 Days
Using tabs with your popups can work wonders when it comes to growing your ecommerce email list. Here's how tabs helped one brand land 1,000 extra subscribers in just 30 days.

List Growth
Jul 07, 2020
Mobile Popup Best Practices: 9 Tips For Designing Popups That Convert
If you don't have popups that are specifically designed for mobile, you're missing out. These best practices for creating mobile popups will help you capture more emails and drive more sales.
Case Studies
Real stories from real Privy merchants

Case Studies
May 02, 2023
How Kōv Essentials Grew From 0 to 7 Figures in 1 Year With Privy
Get a behind the scenes look at how Kōv Essentials uses Privy and the marketing strategy that grew their brand from 0 to 7 figures (and beyond).

Case Studies
Apr 21, 2023
How Bdellium Tools Drove Over $1M in Sales And Made The Switch To Privy
After using Privy Convert on their website for 3+ years, the Bdellium Tools team came to Privy looking for an alternative to Klaviyo. We had the chance to sit down with Ivan to hear more about the switch and how they generated over $1M in sales using Privy.

Case Studies
Apr 10, 2023
How Bryght’s Segmentation Strategy Grew Revenue by 1500% for BFCM 2022
Get an inside look at Bryght's journey using Privy and their Black Friday Cyber Monday campaign strategy that drove 1500% growth year over year.
Product News
Keep tabs on product releases and other updates from the Privy team.

Product
Dec 19, 2023
The 2023 Highlight Reel: Major Wins For Shopify Stores Using Privy (And What To Expect In 2024)
2023 was packed with major highlights to help Privy customers win. Here's the full 2023 highlight reel with product enhancements and content milestones. Plus, trends to look out for in 2024.
Email Marketing
Oct 13, 2023
How to Create a Stunning Email With Privy: 15+ Design Tips and Best Practices
A well-designed email is key to communicating with your audience, building engagement and trust, and driving sales. Learn these 15+ tips and tricks for creating beautiful and effective emails in Privy.
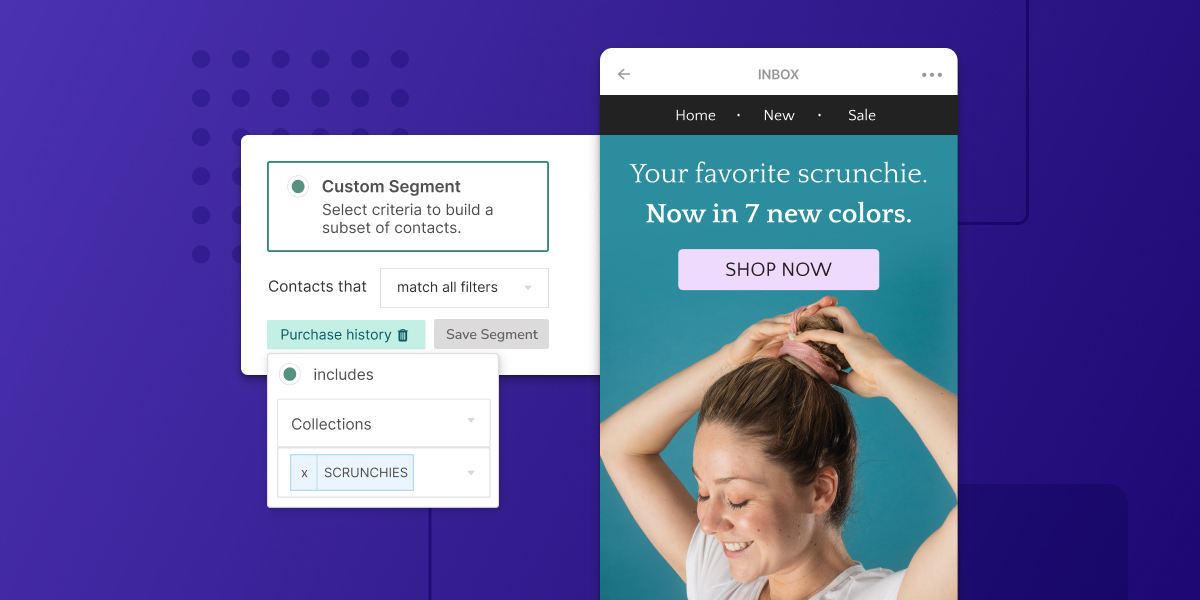
Ecommerce Marketing
Nov 01, 2022
8 Ways To Use Shopify Collections For Your Campaigns And Automations
Using Shopify Collections across your email and SMS campaigns allows you to send more relevant content to your audience. Here are 8 ways to use Shopify Collections in your Privy account to create a killer experience.

Product
Oct 25, 2022
Introducing Shopify Collections For Privy: Everything You Need To Know
Using your Shopify Collections with Privy just got a whole lot easier. Learn how to set up your collections and start using them to send more personalized emails and texts with Privy ASAP.
Recent Articles

Case Studies
Apr 16, 2024
How Truly Lifestyle Brand Uses Privy To Build Relationships AND Generate $1.2M+ In Sales
In just 1 year, Truly Lifestyle Brand has seen serious results with Privy. Here's how they've built strong relationships with their audience and brought in over $1.2M in sales.

Case Studies
Mar 28, 2024
Jewelry Brand Nadaré Co’s Exact 7-Figure Privy Playbook (with Examples)
Nadaré Co. has amassed tens of thousands of contacts for their email marketing list and generated over $1 million in revenue with Privy. This is their exact playbook.
Product
Dec 19, 2023
The 2023 Highlight Reel: Major Wins For Shopify Stores Using Privy (And What To Expect In 2024)
2023 was packed with major highlights to help Privy customers win. Here's the full 2023 highlight reel with product enhancements and content milestones. Plus, trends to look out for in 2024.
