
.jpg)



All-in-One Ecommerce Marketing Platform
Privy is the Fastest Way To Grow Sales With Email & SMS
Get the ecommerce marketing platform built for stores that need to grow sales now. Grow your contact lists, save abandoned carts, send money-making emails & texts, and more – all in one place.

Over 18,500 five star Shopify reviews
What can Privy do for your online store?
Get access to all the Email, Conversion, and SMS tools you need to increase sales at each stage of your customers' journey.
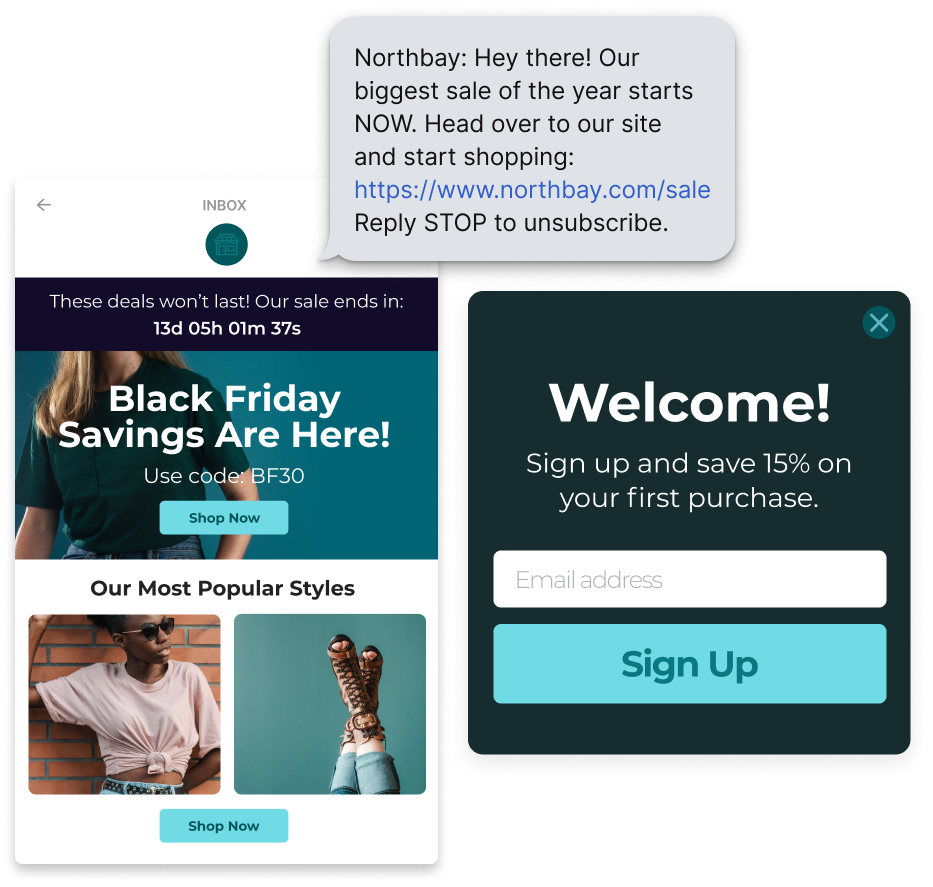
Grow your email and SMS lists faster
Turn casual browsers into loyal subscribers with customizable popups, flyouts, and other high-converting displays.Welcome incentives
Incentivize new visitors to buy from your Shopify store. Offer a first-time discount in exchange for an email or phone number.
Interactive spin-to-wins
Signing up for your email or SMS list should be fun. Add an interactive spin-to-win wheel and customize your prizes however you want.
Mobile-optimized popups
Whether someone shops on their desktop, smartphone, or tablet, their experience wont be inhibited by Privy popups.
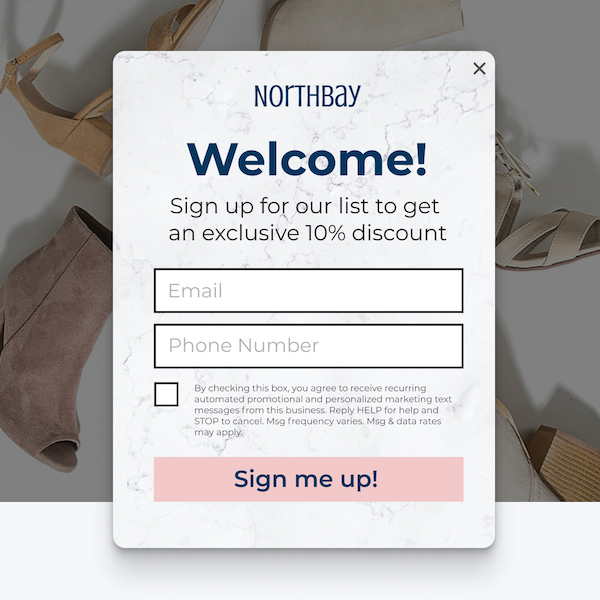
Let your subscribers be the first to know
Communication is key if you want to retain customers. Privy gives you all the tools you need to stay in front of them.Welcome email series
Add a first-time coupon offer, tell your brand story, and create a connection that will keep your email contacts engaged.
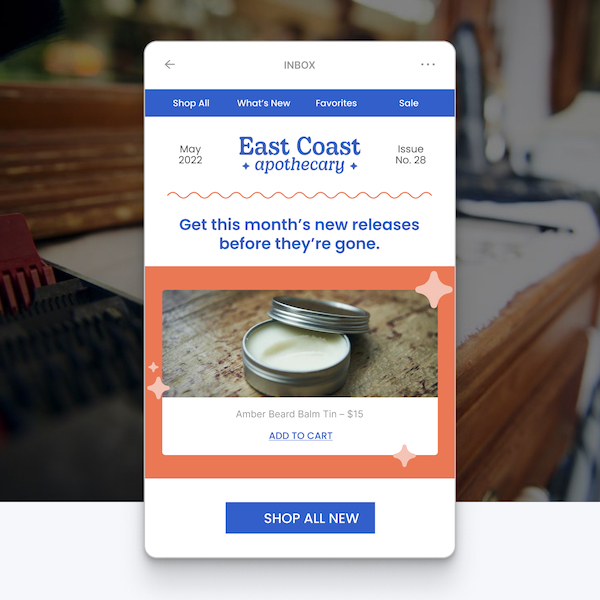
Brand newsletters
Announce new products, seasonal sales, limited-time offers, and other money-making promotions with newsletter emails.
Broadcast text messaging
Send marketing and sales texts to your SMS subscribers. Broadcast text is the perfect complement to your email newsletter.
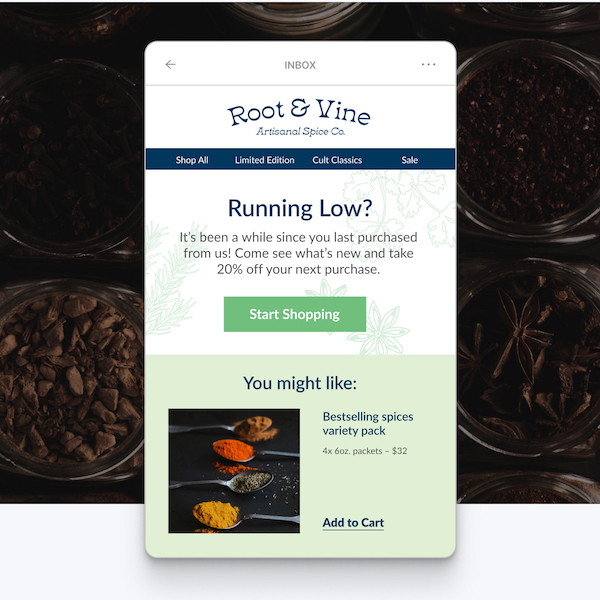
Get shoppers to buy more from your store
Give customers the nudge they need to add more items to their carts and finish their purchases.Abandoned cart texts & emails
Notify shoppers in your email or SMS list when they've left items in their carts. Automate emails or texts to send after a specified period of time.
Cart-saver campaigns
Stop cart abandonment before it happens. Cart-saver popups show when someone is about to leave your site. Reveal a coupon code in exchange for their contact info.
Cross-sell campaigns
Launch product recommendation popups at your checkout stage that are personalized to the items in someone's shopping cart.
Announce free shipping
Add a free shipping bar to the top of your website and show your shoppers exactly how much they need to spend in order to receive free shipping.
Add a countdown timer
Create urgency on your website with a countdown timer. Shoppers will know they only have a limited-time to take advantage of your offer.
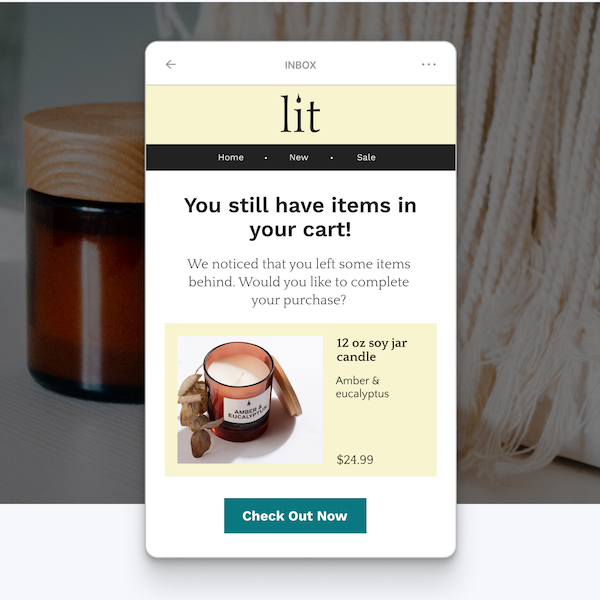
Turn one-time buyers into repeat customers
Your store can't live on one-time purchases. Make buying a habit with emails and texts that keep customers coming back for more.Customer win-back emails
Set up reminders and time-delayed offers to make sure your best customers never go too long without purchasing. Add a limited-time discount to sweeten the deal.
Post-purchase follow ups
Keep customers informed every step of the way with post-purchase follow up emails and texts. Ask for customer feedback on their purchase + a star-rating and review on your website.
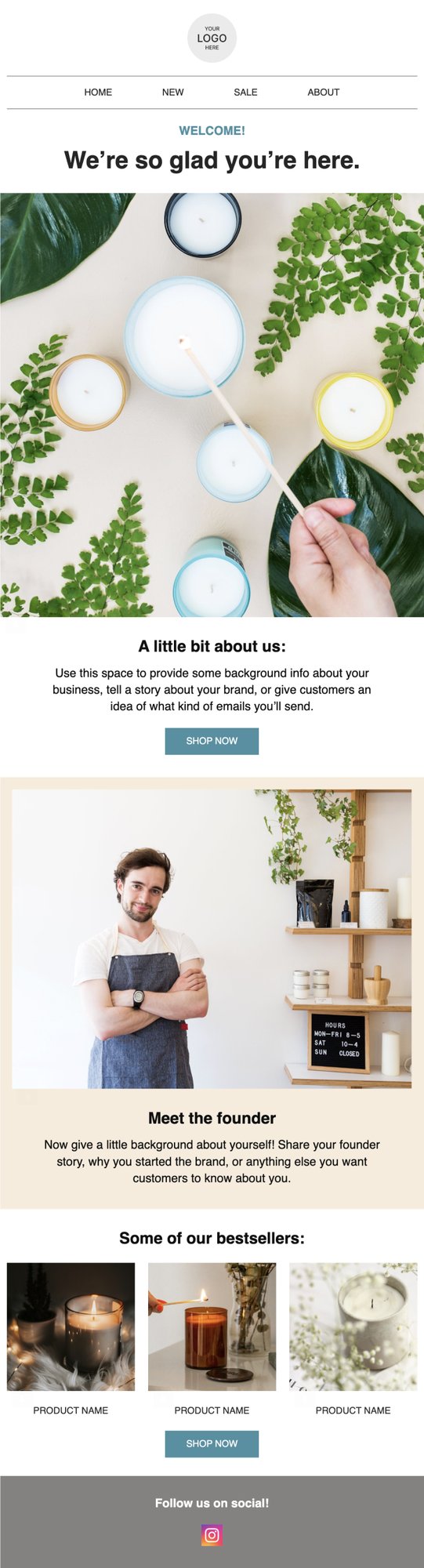
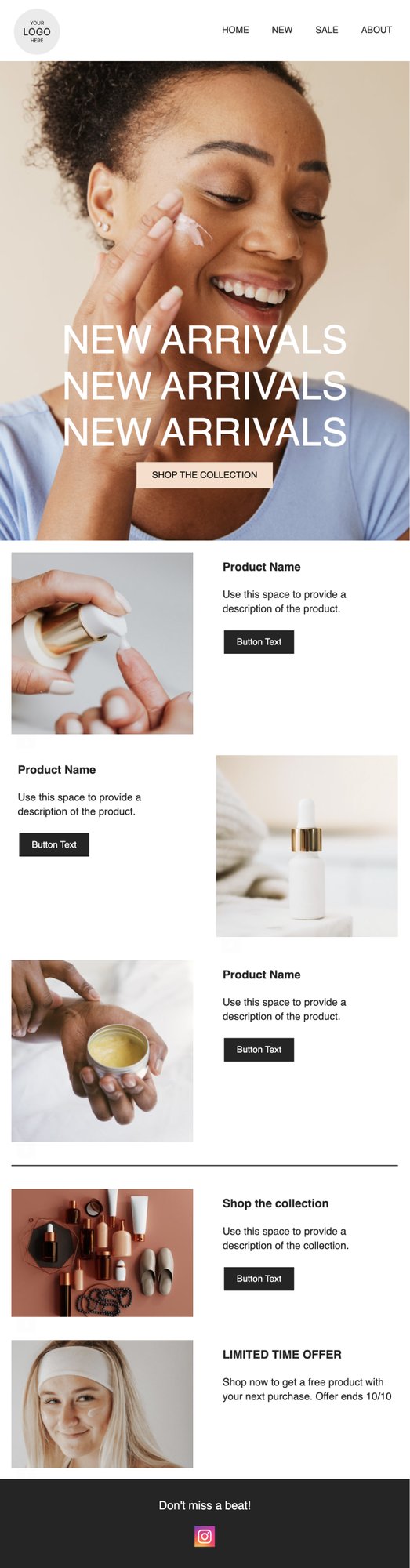
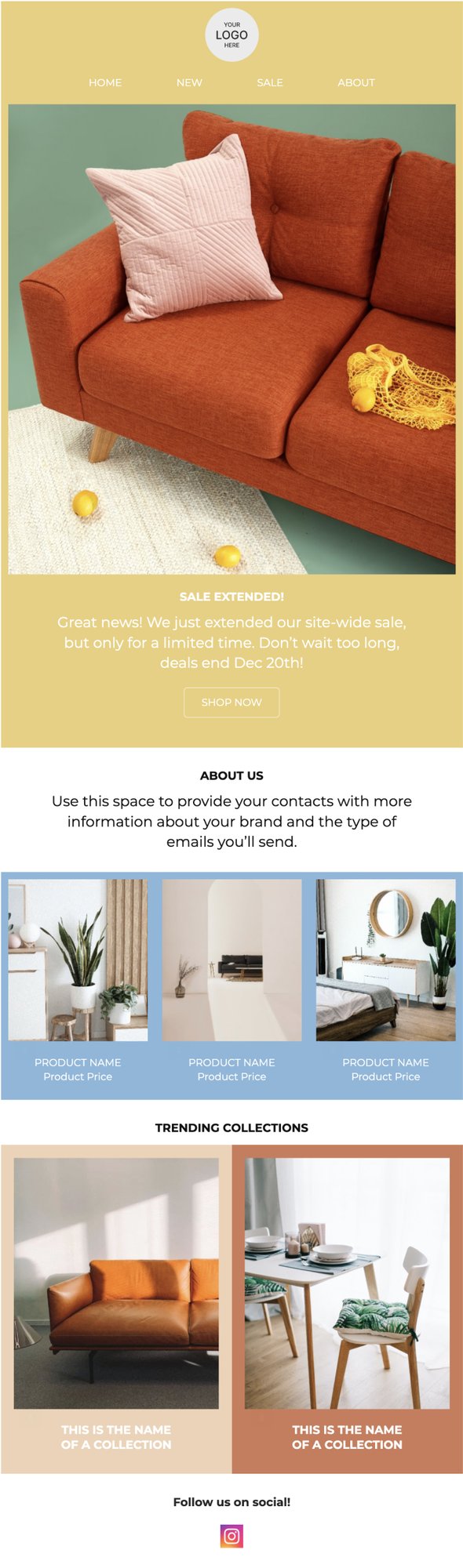
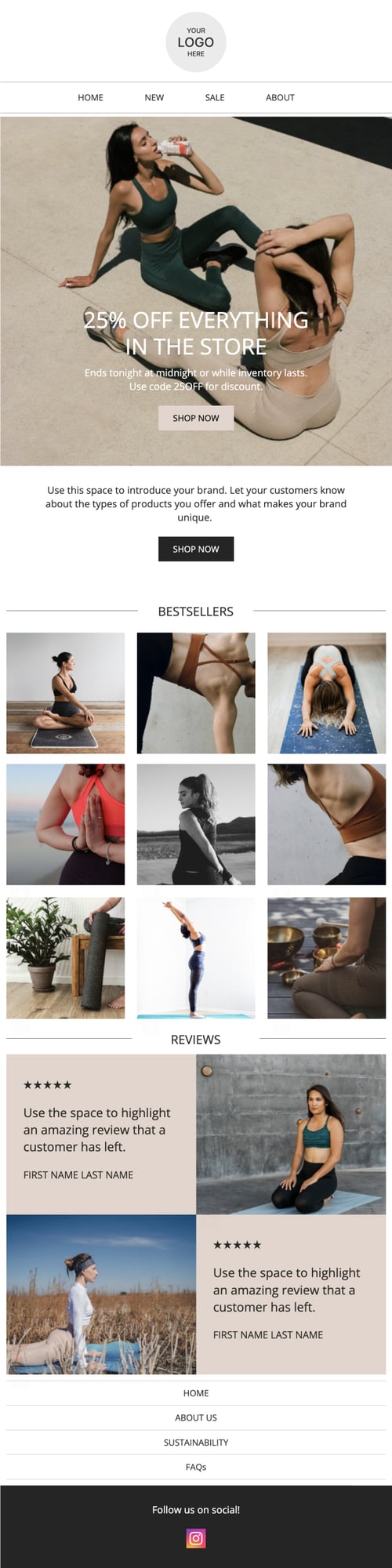
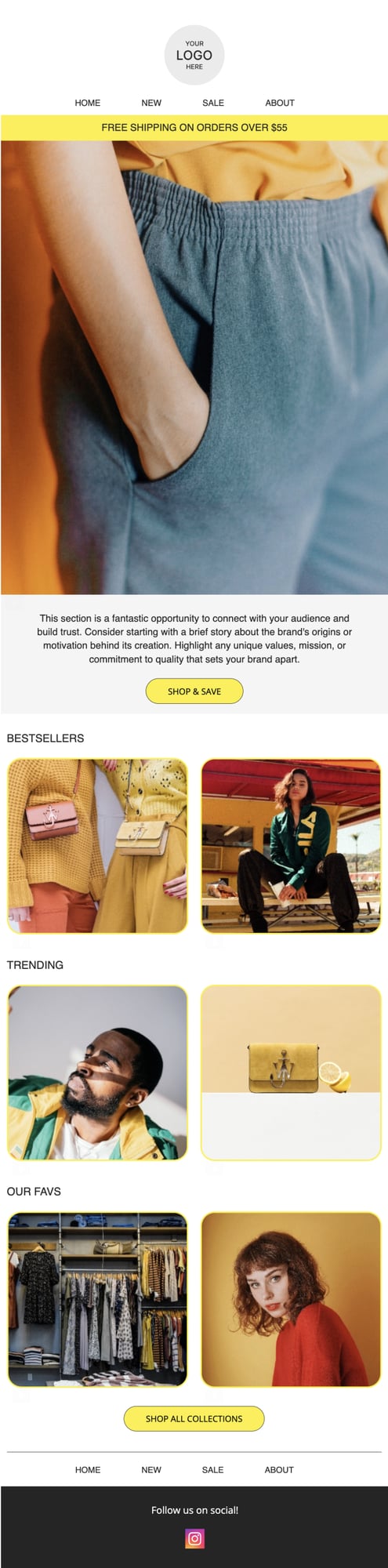
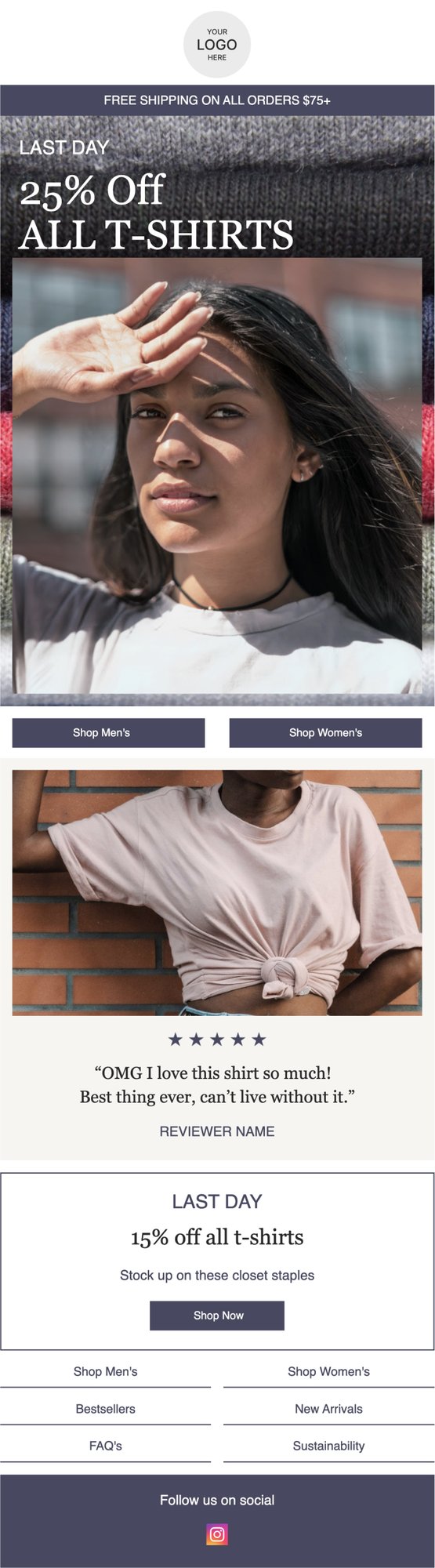
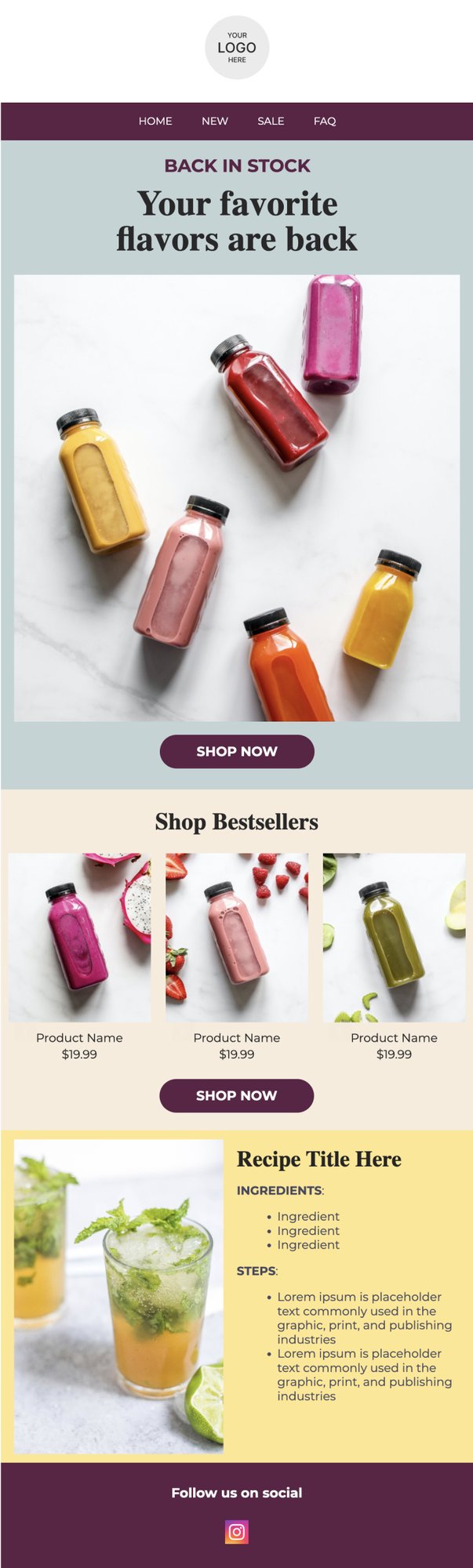
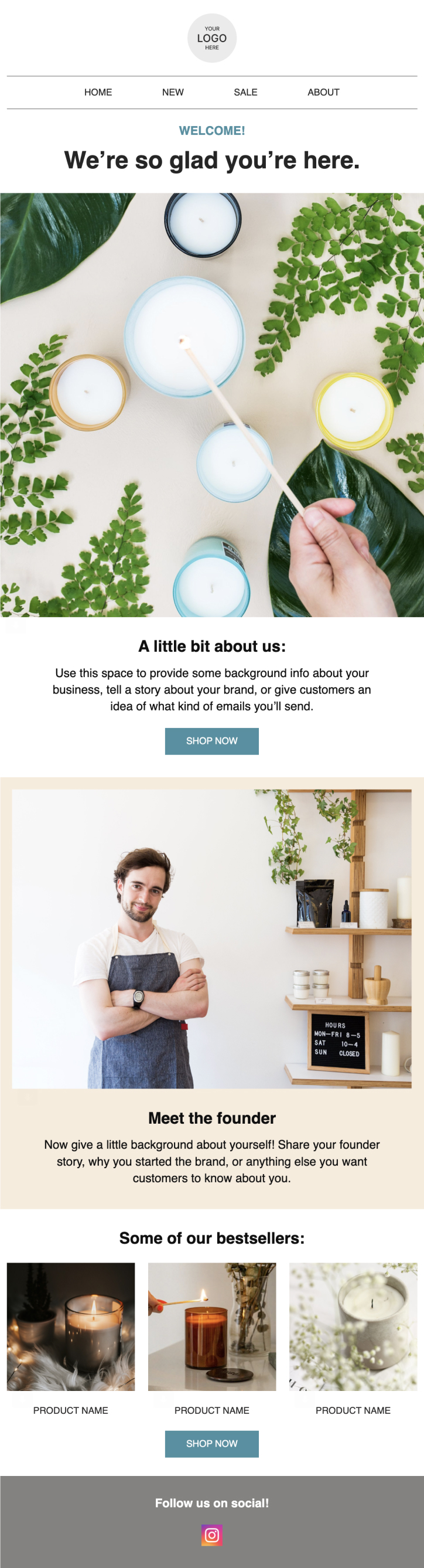
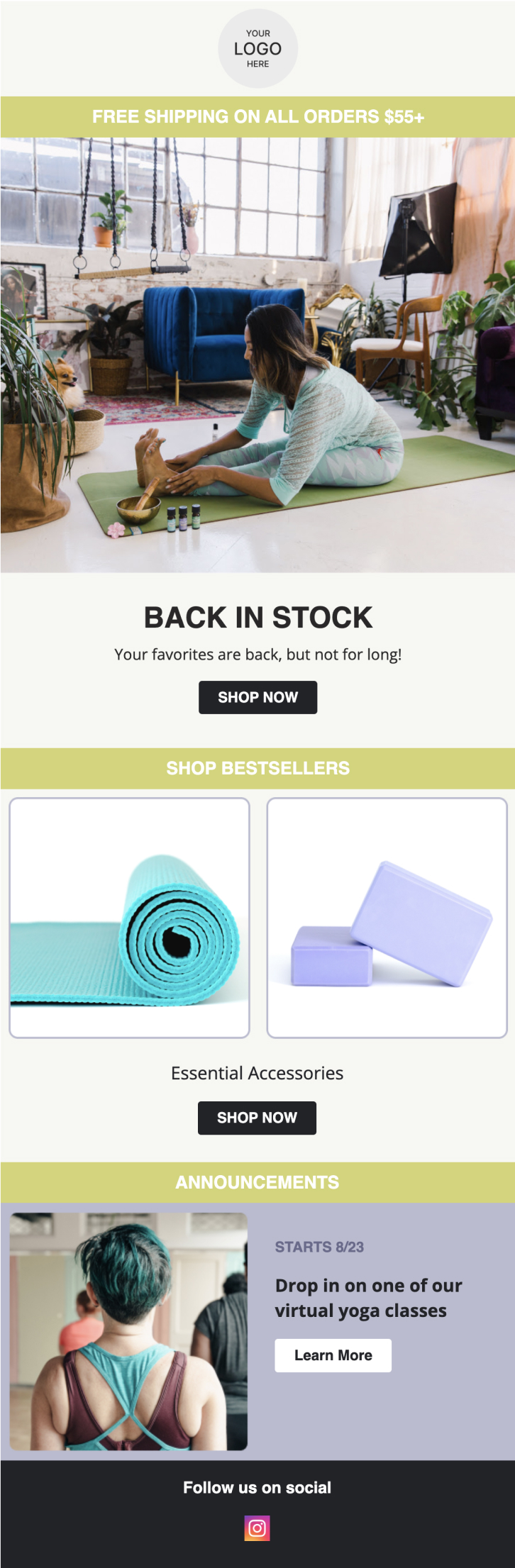
Build beautiful emails in a snap with Privy's library of customizable email templates
Choose from a variety of our pre-built email templates, and customize them to fit your brand with Privy's drag-and-drop editor
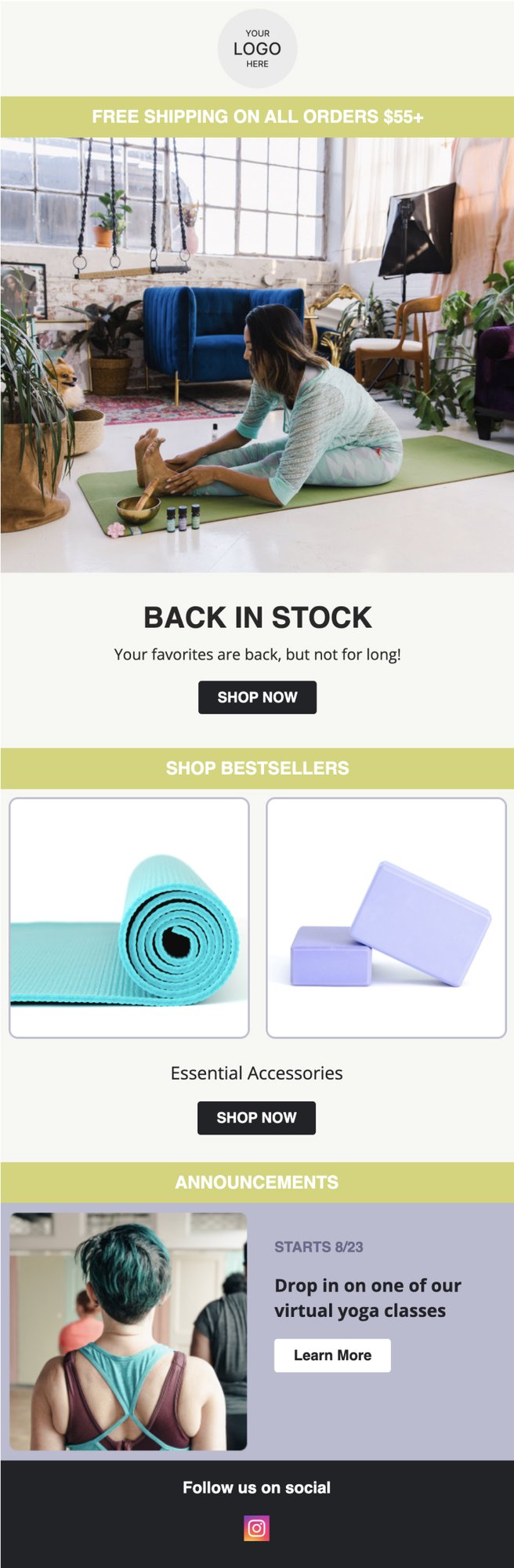



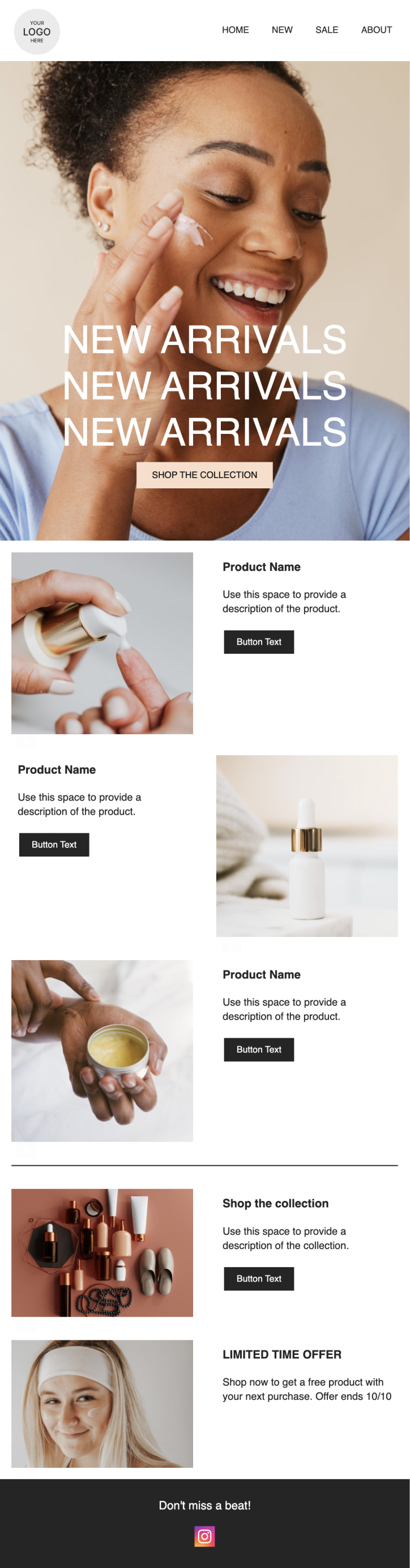

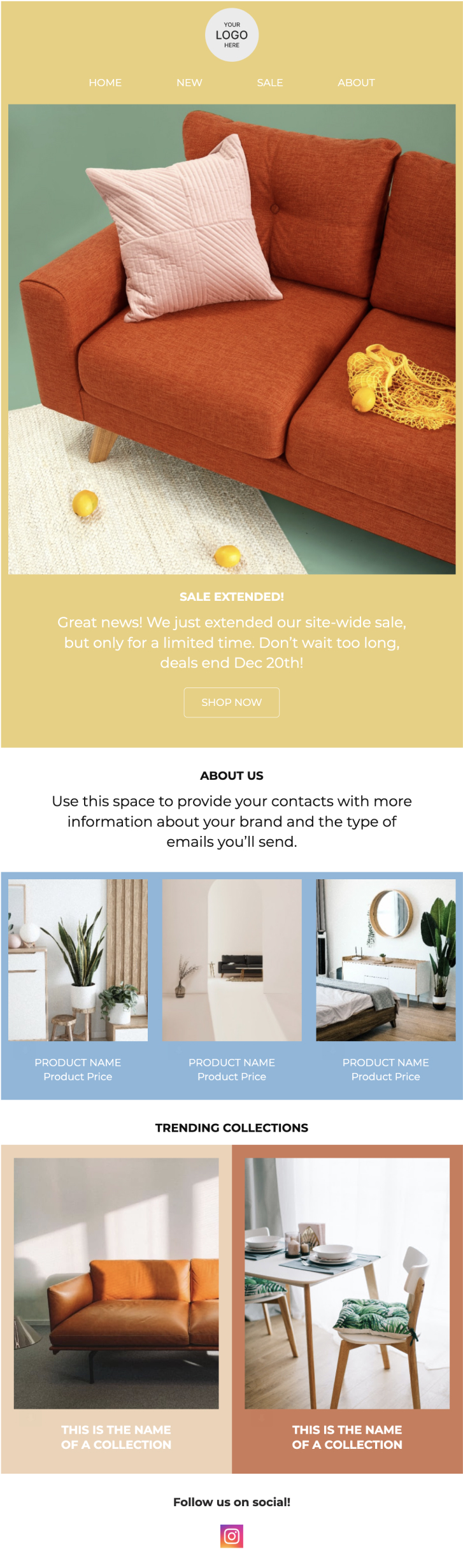
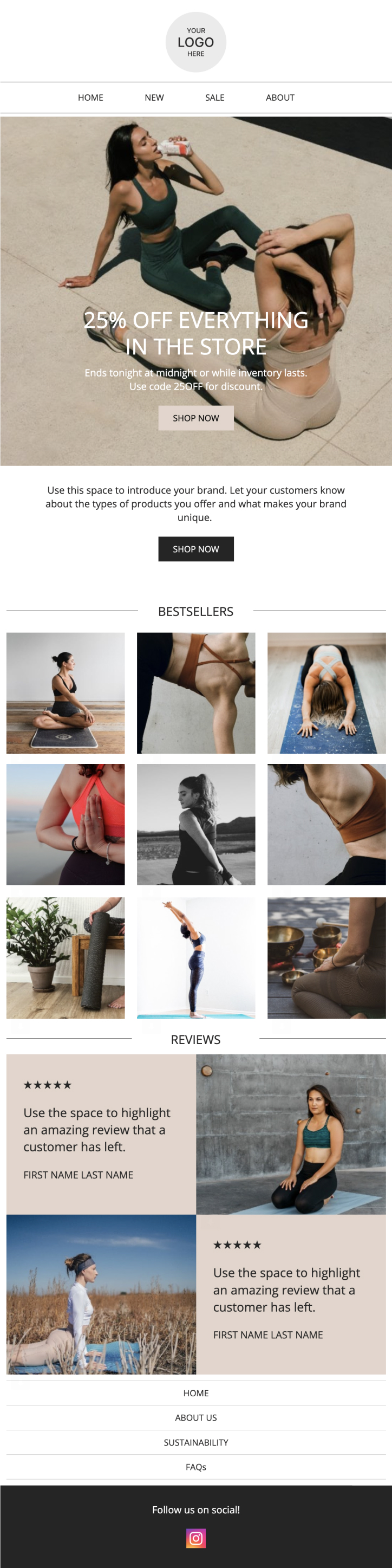
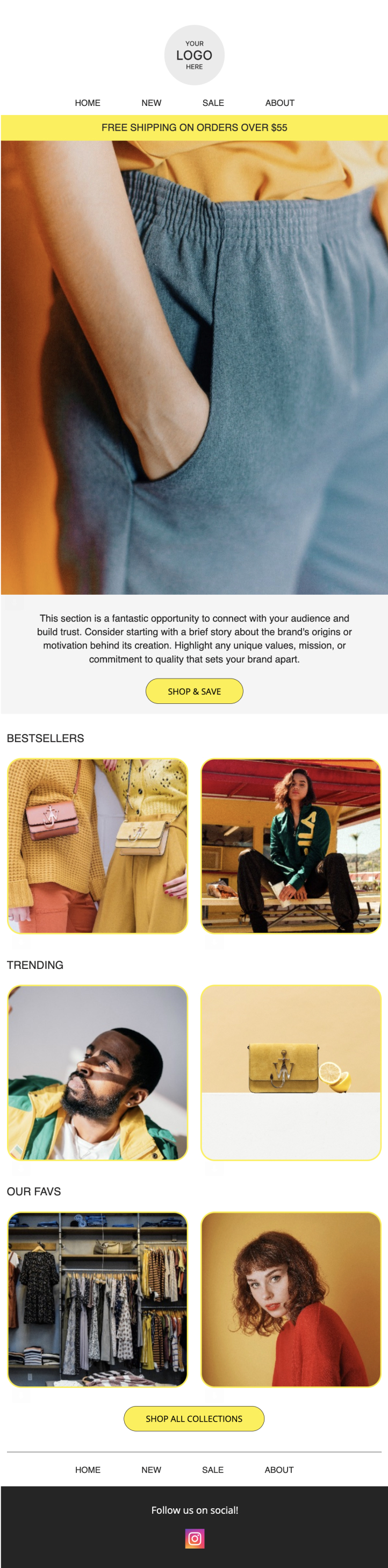

Made to work seamlessly with your Shopify store
Privy’s ecommerce marketing platform has a powerful and direct integration with Shopify to help your brand sell more online, no additional apps needed.

Choose right from your product catalog
Insert products from your Shopify store into an email in just two clicks.

Easy-to-understand revenue reporting
See exactly how your email & text marketing campaigns are paying off.

Automated abandoned cart emails & texts
Automatically email or text shoppers who left items in their cart, even if they haven’t started the checkout process.

Create unique or master coupon codes
Control who gets your coupons and how they are shared. Send recipients their own unique coupon code that automatically syncs with your store.
Case Studies
Read stories from real brands who have had real success using Privy



Get coaching & support from ecommerce experts, no matter where your Privy journey begins





